to be continued….
谈谈servlet
一、 什么是servlet?
Servlet ,全称 Java Servlet. 是由Java编写的服务端程序。其主要功能在于交互地浏览和修改数据,生成动态web内容。 狭义的servlet是指Java实现的一个接口,广义的servlet是指任何实现了这个servlet的类,一般情况下人们将servlet理解为后者 wikipedia
二、servlet生命周期
wikipedia
1 | 当servlet被部署在应用服务器中以后,由容器控制servlet的生命周期。 |
1 | serlvet的生命周期是由被部署到的容器所控制的,当一个请求映射到一个servlet的时候,容器将会执行以下几步 |
三、 servlet是否是线程安全的?
默认情况下,servlet不是线程安全的,尽管在servlet引擎中只有一份servlet的拷贝,但是一个serlvet实例中的方法在同一时间是会可以执行数次的,直至达到内存限制,并且每次执行都是不同的线程来执行。因为Java编程语言是管理内存的,所以这种对系统资源的高效使用是有风险的。因为servlet实例所拥有的变量在每次引用时是会被传递的,这样就带来不同的线程有可能会覆盖同一块内存区域的副作用。所以为了保证servlet的线程安全,需要做到下面的其中任意一种
- 对所有实例变量的写操作进行同步
- 使用SingleThreadModel创建一个单线程的servlet 不过这样并行度会大大降低,所有传入的请求必须等待有空闲的实例才可以继续执行业务
oracle官网
四、 doGet和doPost有什么区别?
其实就是针对http请求中get和post进行分别处理
其实就是get和post的区别
浅淡MySQL中的隐式类型转换
问题的提出
最近在工作当中,无意发现varchar类型的字段,如果与数字进行等值比较,得出来的结果跟预期不一致。当时很是好奇,于是工作之余将此问题原因查明,并作为记录
举例说明
这里就不再取公司的业务数据作为例子,而是直接找到了mysql官网中的例子如下所示
1 | SELECT '9223372036854775807' = 9223372036854775807; |
-> 1
1 | SELECT '9223372036854775807' = 9223372036854775806; |
-> 1
我们可以清晰的看到两个等式左侧的字符串的值是相等的,但右侧的数字却不相等,但是两个等式比较结果确是相同的,如果我们用这种方式(varchar列与数值进行比较运算)来做等值比较,那么产生的结果很可能不是我们预期的内容
官网解释
Comparisons between floating-point numbers and large values of INTEGER type are approximate because the integer is converted to double-precision floating point before comparison, which is not capable of representing all 64-bit integers exactly. For example, the integer value 2^53 + 1 is not representable as a float, and is rounded to 2^53 or 2^53 + 2 before a float comparison, depending on the platform.
我理解这里的大致意思是说,在浮点数和大的Integer类型的数值发生比较的时候,得到的结果是一个近似的结果。
在integer数值与浮点数进行比较之前会被转化为双精度浮点数,这就导致转换后的结果不能精确的表示所有64位整数,举例来说,整型的2^53 + 1是不能被浮点数表示的,发生浮点整数比较时会被近似为2^53或2^53 +2,具体结果视平台不同而不同
看到这里可能会比较疑惑,我明明用的是一个字符串列与数值进行比较,怎么就跟浮点数和整数扯上关系了?我们继续读官方文档
这里在官方文档前面其实描述了,我在这里就直接给出我的理解了,官网的具体链接放于文章末尾,感兴趣的同学可以自行去阅读
当发生比较运算时,以下规则描述了类型转换是如何发生的:
- 如果运算符两侧的操作数有一个或一个以上为NULL,比较结果则为NULL(如果是NULL-safe运算符<=>则不会出现上述结果,select NULL <=> NULL;结果为1,并且不会发生类型转换);
- 如果运算符两侧的操作数都是字符串,它们会被当作字符串比较;
- 运算符两侧都是integer,它们会被当作integer来比较;
- 16进制的value如果不与数字发生比较会被当作二进制串处理;
- 如果其中一个操作数是timestamp或者datetime并且另外一个操作数是常量,常量会被先行转换为时间戳在进行比较,这么做是为了对ODBC更为友好 但这种操作并不支持in()查询,为了安全起见,在这种比较的时候,请尽量使用完整的datetime、date或者是time的字符串来进行比较。举例来说:在date或者是time数据间进行比较的时候,如果想达到最好的比较效果,请尽量使用显示的类型转换(cast )来将两个操作数转换成想要比较的数据类型;
- 一个单行的子查询将不被被当做constant来处理,举例来讲,一个datetime类型的数值和一个返回一个integer类型的子查询,会被当作两个integer数来进行比较,这个integer数将不会被转化为临时变量,如果想要当作datetime类型进行比较 请使用cast进行显示的类型转换;
- 如果操作数中有decimal,这种比较运算将根据另一个操作数的类型来决定。另一个操作数如果是decimal或者integer,则比较会被当作decimal类型进行比较,另一个操作数如果是float类型,则会被当作float类型进行比较;
- 所有其他情况,均会被当做浮点数进行比较,举个例子来讲,一个字符串和一个数字进行比较会被当作浮点数来进行比较
那么通过上述规则,我们不难看出,在用varchar列与数字进行比较的时候则会被当作浮点数进行比较,那么这种情况发生的时候,它们每次并不一定是同一结果,integer操作数会被CPU转换为浮点型,而string的转换会以浮点数的按位乘法的方式进行转换,此外,操作结果还会受到计算机架构、编译器版本、编译器优化等因素的影响。
要想避免这种情况,其中的一种办法就是避免这种浮点数的隐式转换发生,比如我们最开头的例子:
1 | SELECT CAST('9223372036854775807' AS UNSIGNED) = 9223372036854775806; |
小结
其实我之前之所以没遇到这种问题,完全是因为我自己在写查询语句的时候,使的SQL语句的语义尽量地准确,比如varchar类型的列,我就只使用字符串与之进行比较运算,这就完全规避掉了这种隐式转换的发生,这里其实并不是说楼主水平有多么好或者吹嘘自己,而是想说保持一个良好的编码习惯会为自己避免很多问题的发生,节省很多时间,但是辩证地来看,若经常保持不良好的编码习惯,也能经常收获一些意想不到的问题,这个时候如果肯下点功夫,虽然花费了大量精力去处理问题,但却能收获到一些良好编程习惯接触不到的知识。但无论是采用哪种编码习惯,遇到问题的时候一定要下功夫去查明真相,如果当时没有精力去查明这种问题,工作之余一定要将问题查明原因,否则任你工作经验再多,积累的无非只是”工作年份”而并非”工作经验”
参考文章
聊聊线程池
在开始做这期博客之前,作者提出了几个问题,文章将通过这几个问题穿插着了解线程池
线程池是什么?
为什么要用线程池?他解决了哪些问题?
有哪些默认的线程池?他们有没有什么问题?
线程池工作流程?
work工作流程?
线程池的参数有哪些?生产环境该如何根据业务调整这些参数?
进入正题
1. 什么是线程池
计算机科学中,线程池是一种为了取得应用程序并发度的软件设计模式。它也被成为replicated workers or
work-crew model,一个线程池在其内部维护这一组为了等待执行并发任务的线程,通过对这一组线程的维护,
这种模式提高了性能并且避免了短任务频繁创建及销毁的执行延迟。
线程池是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,比如MySQL。
池化思想
顾名思义,将资源统一在一起管理解决资源分配的问题,最大化收益并最小化风险。
池化思想不仅可以用在计算机领域,也可以用于人力管理、工作管理设备、金融管理(例如将RD认为是一种资源,将所有RD统一放入池子里统一管理,分配开发任务等等),其他几种使用场景包括以下:
- 内存池(Memory Pooling) : 预先申请内存,提高内存申请速度,减少内存碎片
- 连接池(Connection Pooling) : 预先申请连接信息,提升申请连接的速度,降低系统的开销
- 实例池(Object Pooling) : 循环使用对象,减少资源在初始化和释放时的昂贵损耗。
2. 为什么要用线程池? 线程池有什么好处?
- 降低资源损耗 通过池化技术重复利用已经创建的线程, 降低线程创建和销毁带来的损耗。
- 提高响应速度 任务到达时,无需等待线程创建即可立即执行
- 提高对线程的管理性,线程是稀缺资源,无限制的创建不仅会消耗系统的资源,并且还会因为资源分配不合理导致调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控
- 提供更多可以调控的功能,线程池具备可拓展性,允许开发人员向其中添加更多的功能。比如延迟队列,允许任务延期执行
3.有哪些默认的线程池
在Java当中,主要通过类Executors提供的几个工厂方法来创建默认的线程池,其中JDK1.8中主要提供以下6种默认的实现
- newSingleThreadExecutor
- newFixedThreadPool
- newWorkStealingPool
- newSingleThreadScheduledExecutor
- newScheduledThreadPool
- newCachedThreadPool
这些工厂方法都是通过ThreadPoolExecutor实现的,只是不同的方法构造参数不尽相同
文章未完成待续….
to be continued
聊聊ORM框架之mybatis
前言
周五本来想着跑个步就打算睡觉来着,没想到还能跟前同事大佬在一起交流一波技术(其实是单方面的吊锤我,哈哈),大佬带我系统的分析了几个常见框架的源码,今天正好趁热,赶紧把已经了解的内容记录下来,便于以后进行查阅
ORM
在正式了解mybatis之前,其实需要先了解一些概念,比如什么是ORM(Object Relational Mapping,简称ORM)
wikipedia
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。
阮一峰的网络日志《ORM实例教程》
在面向对象编程语言当中,所有的实体都可以被视作对象,而关系数据库当中,则是通过实体与实体间的关系来连接数据,很早就有人提出,关系也可以用对象来表达,这样的话,就可以通过面向对象的思想来操作关系型数据库。
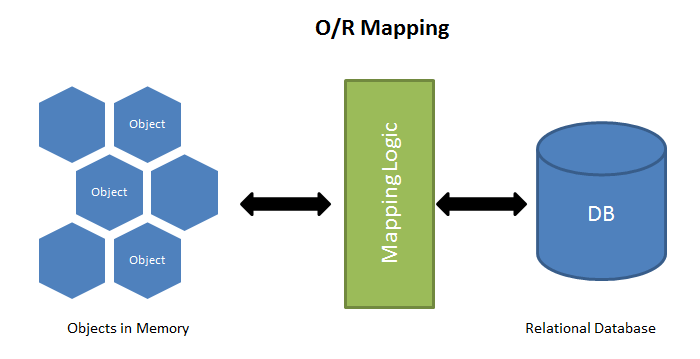
也就是说,ORM是通过实例对象的语法,来完成关系型数据库操作的技术。
- 数据库中的表 —》 类
- 数据库中的一行记录 —》 对象
- 字段 —》 对象的属性
在Java编程语言中,常用的ORM框架无非两种,一种是Hibernate,一种是Mybatis,前一种是拥抱面向对象的,它能够维护Object—> Relation和 Relation —> Object的映射,是完整的ORM框架,而Mybatis则不是这样,mybatis只实现了Relation—> Object这一部分内容,它是拥抱SQL的,所以说Hibernate是完整的ORM框架,而Mybatis是不完整的ORM框架,Hibernate这种接近面向对象的操作方式也使得它拥有一系列的优点(HQL语言),但是由于经常使用HQL语言容易使得对底层SQL的细节忽略,从而导致一些SQL在出现性能问题后优化会非常困难,由于本节只讲mybatis,所以hibernate和mybatis的对比区别这里就不再过多赘述了。
mybatis框架的工作流程
由于现阶段用springboot比较多,我们现在就拿集成已经非常方便的mybatis-spring-boot-starter来进行本文的讲解,代码版本
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.3</version>
</dependency>其实一聊到springboot,想到的第一件事就应该是自动装配,那就需要看一下mybatis是不是有mybatisAutoConfigration,果然这里有自动配置类-》org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration
MybatisAutoConfiguration配置类在当前环境下如果发现DataSource类加载后,会进行自动装配,默认会加载SQLSessionFactory和SqlSessionTemplate,
SqlSessionFactory是生产SqlSession的工厂,可以创建Sqlsession(mybatis核心接口,通过这个接口可以执行命令,获取mapper或者是管理事务)
SqlsessionTemplate则实现了Sqlsession、DisposableBean接口,在构造方法内创建了一个代理SqlSessionInterceptor,通过该代理类代理执行statement
sqlsession提供的接口方法
sqlsessionTemplate类图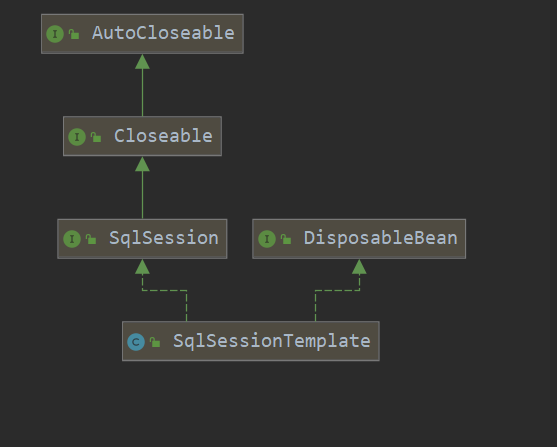
谈谈找工作的那些事儿
写在最前面
我是cris,一名毕业于双非二本的后端工程师,说来惭愧,我今年也被动加入了找工作的大军,今年找工作确实是不同于以往,估计也有很多人像博主这样也是因为疫情公司倒闭或者裁员之类的原因在家里待业,鄙人不才,今年花费了79天面了8,9家公司,才收获到2份offer,不过自己还是没能达到自己想要到达的高度,在面试的过程中也发现了自己的很多不足(博主一面试就被问到了自己的知识盲区,博主你的知识盲区怎么这么多啊我摔),于是写一篇博客记录并以此警醒自己。
关于选择
这一次,放在博主面前的是两份offer,一个互金,一个央企,博主并没有像之前那样因为薪酬更高选择那份薪水更高的那份互金offer,而是选择了入职央企,其实挺不甘心的,因为今年没能进到大厂,不过自己也确实没有付出太多的努力,想想自己其实也是满惭愧的,身边的同事今年即使是疫情也跳到了一线的互联网大厂,只有我选择了央企,同事大多都不是很理解,因为选择了央企就是选择了稳定,选择了更少的薪酬,选择了更多的业余时间,不过这样就可以去做一些我自己没能完成的事情了吧,其实这里其实是为了博主自己找的借口,还是时间管理的问题,其实在哪工作都一样能学习,都一样能够跳槽去一线的互联网大厂,所以既然选择了,希望博主真的能够刹下心来,在业余时间多学一点东西,把游戏戒掉。
关于现在的工作
在互联网公司待习惯了,干好自己分内那点事情似乎就已经是必然了,至于产品怎么样,数据怎么样仿佛就跟我一点关系都没有,这样的想法似乎在我的脑子里已经很稀松平常一样,到了央企后,所有的事情似乎都变得不一样了,做了一些原来没有想过的事情,原来不想要做的事情,写文档,画流程图,写ppt,这似乎是以前我最不喜欢做的事情,但转念一想,是不是过去的想法太天真了,过去思考的事情太少了,思维模式需要发生变化了,不应该再只用一个开发的想法去做事,而是以一种统筹的角度来做事情,做一些从前没做过的事情,甚至是做自己不喜欢甚至抵触做的事情,恐怕只有这样,一个人才能够成长吧?
学会系统性成长
这么回想起来,我已经是第二次体会失业了,想想在不做客户端开发的这些年,在技术上面我好像还是没有太多成长,又开始浑浑噩噩起来,一年工作经验用十年,每次对于自身的提升仿佛都是功利性的,为了找工作而学习,为了找工作而找工作,却忘记了自己学习真正的目的,这样又怎么能够做好技术?怎么能够写出一手好代码呢?当然我学技术并不是只为了能够找到一个开发的岗位,每个月有一定的工资,能够填饱肚子,如果只是这样,那和咸鱼又有什么分别呢?所以,其实这次失业是偶然也是必然,算作对作为一个技术人没有一点点技术上更高层次的追求的一个教训罢了。跟身边优秀的人对比起来,想想自己没能进入大厂其实是必然的,没有转变自己的思维认知,没有对个人的系统性成长,那么这个人又怎么能够拥有核心竞争力呢?
不要放弃自己
失业时间长不过是自己能力差的表现,永远不要把这个原因归结到环境因素上面。记得前公司的组长曾经“这样”跟我们聊过,“世上无难事,只要肯放弃”,是啊,如果一遇到了难题就选择了逃避,选择了放弃,那么这个人什么时候才能成长呢?今年刷头条,据说有500w北漂因为疫情影响回到了自己的家乡,放弃北漂,其实如果有希望的话,目测谁也不会选择放弃北漂吧,来到北京的北漂们大多有一个能留下的梦,但是在现实面前(高房价,中年危机,刚需结婚),又有几个人能够继续留下来追梦呢?还记得当年还是在做客户端开发的时候,那是博主第一次体会到了失业的危机感,那时候还没毕业正值毕业季写论文的时候,当时觉得那家公司薪水太低,选择了离开,然后在北京花了1个月时间投简历找工作,然而还是没能找到一份工作,只好回学校一心写毕设。如果博主这次还像毕业时那样放弃了,是不是也就“那样”了?
写在最后
相信有很多像博主一样的朋友,在北京一样迷茫、彷徨着,大家每天做着同一样的北漂梦,当有一天我们不得不离开北京的时候,又或者我们终于实现的北漂的终极梦想的时候,面对自己当年的选择,不要后悔,不要带着遗憾离开!
谈谈引用
前言
说来惭愧,最近在面试中在JVM基础上面又栽跟头了,尤其是在引用这方面,之前觉得引用这里比较晦涩难懂,枯燥乏味,每次看到JVM中的引用部分内容时,总是会选择性地跳过,所以看起来这次的跌倒是注定的,好,那么废话不多说,我们今天就来尝试弄懂引用这一块内容
何谓引用?
如果reference类型的数据中存储的数值是另一块内存的起始地址,那么这块内存就代表着一个引用。
这种定义就比较纯粹,因为他只能代表被引用或者不被引用两种状态,对于一些“食之无味,弃之可惜”的对象就无能为力了,也就是说我们希望能够描述这样的一类对象:内存空间还足够的时候,则这些对象还可以保存在内存之中,如果内存空间在进行垃圾回收之后还是很紧张,则可以抛弃这些对象,很多系统的缓存功能都符合这种场景,所以在jdk1.2之后,java对引用的概念进行了扩充,将引用分为强引用、弱引用、软引用、虚引用4种,4中引用强度依次减弱
(出自深入理解Java虚拟机)
强引用
强引用就是指程序代码中普遍存在的,类似“Object o = new Object();”这类的引用,只要强引用还存在,垃圾回收器永远不会回收掉被引用的对象,即便内存不足的时候,虚拟机宁愿抛出内存不足的异常,也不会去回收这些对象
使用场景
大部分使用场景都是使用了强引用,比如使用new关键字创建对象,通过反射的方式获得一个对象
软引用
软引用是用来描述一些还有用,但是非必需的对象。对于软引用所关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收,如果这次回收还是没有足够的内存,才会抛出内存溢出异常,jdk1.2之后,提供了SoftReference类来实现软引用
使用场景
有可能在创建后使用的对象,也可能不使用,所以这里基于内存的考虑会使用软引用,常见于缓存方面的使用
弱引用
弱引用就是用来描述非必需对象的,但是他的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作的时候,无论当前内存是否足够,都会回收掉只被弱引用所关联的对象,jdk1.2之后,提供了WeakRefrence类来实现弱引用
使用场景
弱引用作用于生命周期更短的,对内存更为敏感的场景当中,只要一发生内存回收就会回收掉这部分内存,比如占用内存较大的Map,WeakHashMap,ThreadLocal中的ThreadLocalMap中的key都是弱引用
1 | String str = "hello weak reference"; |
虚引用
虚引用也被称为幽灵引用或者幻影引用,它是最弱的一种引用关系,一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。也就是在虚引用锁描述的对象被回收之前,会被JVM放入ReferenceQueue中(其他引用是在引用的对象被销毁之后才被传入ReferenceQueue中),由于这个机制的存在,虚引用大多数被用于引用销毁前的处理工作,另外,虚引用在创建的时候必须带有ReferenceQueue
在jdk1.2之后,提供了PhantomReference类来实现虚引用
1 | PhantomReference<String> pref = new PhantomReference<String>(new String("str"),new ReferenceQueue()); |
使用场景
对象销毁前的一些操作,比如资源释放等