前言
每当我们聊到redis的数据结构的时候,我们总会想到string,hash,set,zet,list,但是我们有没有想过这些数据结构又是怎么实现的呢?今天就来聊一下这些常见的数据结构在底层是怎么实现的
SDS(Simple Dynamic String) 简单动态字符串
基本结构
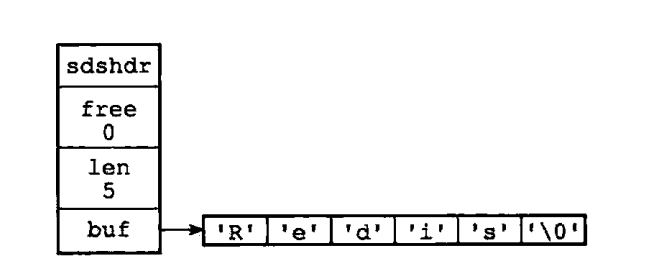
在redis中每个sds.h/sdshdr代表一个SDS值
1 | struct sdshdr { |
不采用C风格字符串的原因
- O(1)时间复杂度获取字符串长度,c风格字符串(char数组)需要遍历整个数组的字符进行计数需要O(n)时间复杂度
- 防止缓冲区溢出和避免手动扩容 使用c风格字符串的时候在对字符串进行修改的时候,比如字符串拼接等等需要自己考虑对字符串数组进行重新扩容,如果忘记扩容会导致与该char数组后的连续内存空间内容被覆盖,会导致一些意想不到的问题,而在使用SDS的时候,API会帮我们检查SDS的空间是否满足所需的修改要求,不满足的话API会自动的将SDS的空间扩展至执行修改所需的大小,所以使用SDS的话既不会产生缓冲区溢出的问题,也不会需要进行手动扩容
- 确保2进制安全 使用len来确定字符串的长度而不是通过buf数组中的’\0’字符
- 减少因修改字符串长度时引起的内存重新分配次数(通过内存预分配机制)
应用场景
- 普通的键值对的键和值都是使用SDS来存储的
- AOF缓冲区也是通过SDS来实现的
链表
链表是数据结构中比较常用的一种,可以想到的特性就是O(1)的增删和O(n)的随机访问,redis中的列表就是通过链表来实现的,双向的无环链表,redis构建了自己的链表实现
基本结构
链表中的每一个节点使用一个adlist.h/listNode来表示
1 | typedef struct listNode { |
多个listNode通过prev和next指针组成双端链表,一般情况下只用多个listNode结构就可以组成链表了,如果使用adlist.h/list来持有链表的话,操作起来会比较方便一些
1 | typedef struct list { |
list提供了头尾指针和链表长度计数器len
特点
- 应用于列表,发布与订阅、慢查询、监视器等场景
- 双端五环链表
- 每个链表用一个list结构来表示,这个结构带有头尾指针和长度
字典
未完待续~